
Storage efficiency technologies are key to modern all-flash and hybrid-flash storage arrays, but the capabilities deployed are always a trade-off. On the face of it 100% inline deduplication and compression look like the best way to go, as you eliminate writing a significant amount of data, equally post-process operations would appear to be inefficient as all the data has to be written, then re-read and ultimately re-written.
The reality is that if you were to do everything inline then you are likely to compromise performance as all the processing is in the write path. You would also need very powerful CPUs and a huge amount of RAM to store the deduplication hash table, which in turn is likely to restrict the size of the drives that can be used, all of which results in higher costs.
You therefore need to balance performance, efficiency savings and cost and the best solutions have a blend of inline and post-process capabilities. NetApp has taken this exact approach with ONTAP and it has evolved over the last two decades to utilise a variety of highly optimised efficiency features for both the all-flash (AFF) and hybrid-flash (FAS) platforms including:
Deduplication
There are five deduplication technologies as follows:
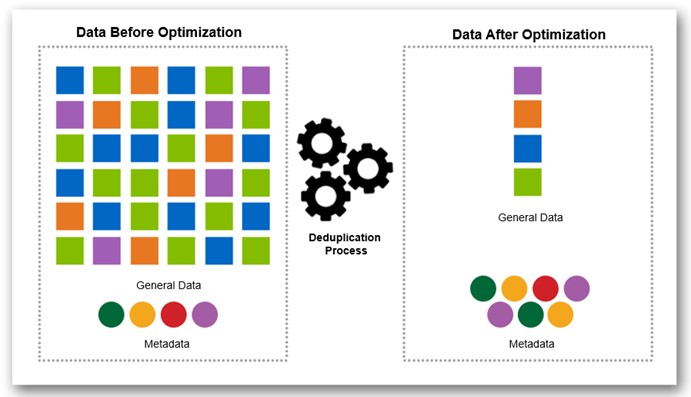
- Inline Zero Block Deduplication
- Zeros are eliminated first, no user data is written to disk and only metadata is updated
- Inline Deduplication (AFF or Flash Pool aggregates only)
- Eliminates duplicate 4K blocks prior to the data being written to disk using a memory based hash table of the most common blocks, the hash table does not contain all blocks therefore all duplicates will not be eliminated. When duplicates are found, a byte-by-byte comparison is performed to make sure that the blocks are identical
- Post-process Deduplication
- Works much like inline deduplication, except it scans data that has already been written to disk and eliminates all duplicates
- Automatic Background Deduplication (AFF only)
- Performs continuous deduplication in the background and throttles the process if foreground I/O needs to take priority
- Cross Volume (Aggregate) Deduplication (AFF only)
- Eliminates duplicate blocks across volumes to make further space savings whereas standard duplication works at the volume level (i.e. within a single LUN or file system only)

Compression
There are six compression technologies as follows:
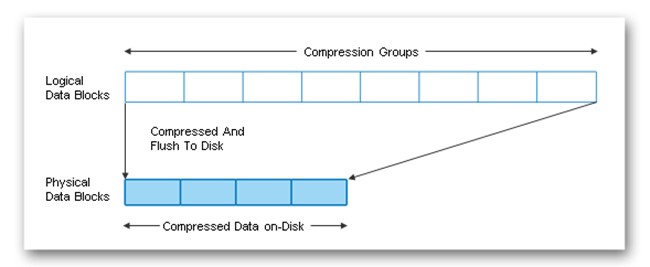
- Adaptive Compression
- The data is scanned and compressed using an 8K compression group which provides a good balance of performance and storage efficiency savings – best for hot data
- Secondary Compression
- The data is scanned and compressed using a 32K compression group which provides much better storage efficiency savings at the expense of more of a performance overhead – best for cold data
- Inline Compression
- Compresses the data prior to it be written to disk
- Post-process Compression (FAS only)
- Compresses data after it has already been written to disk
- Temperature Sensitive Storage Efficiency (TSSE)
- Uses inline Adaptive Compression for the initial write and once the data becomes cold (14 days of inactivity by default) it’s re-written with post-process Secondary Compression to provide the best of both worlds
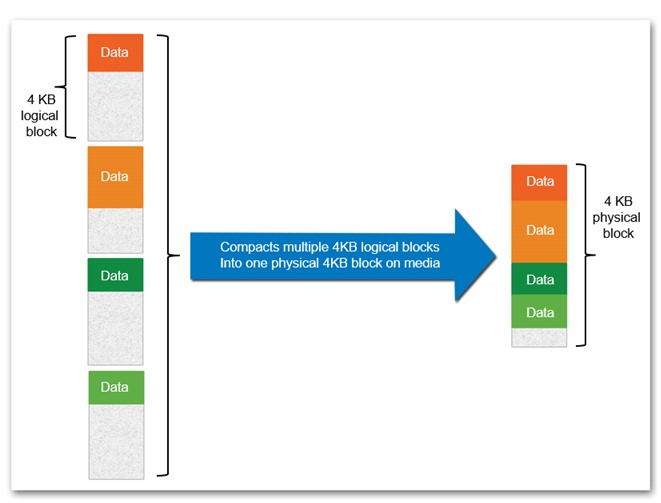
- Inline Compaction
- Takes I/Os that normally consume a 4K block and packs multiple I/Os into one physical 4K block
What are the likely real-world savings you will see?
There is a lot of sophisticated and mature technology here so for most typical workloads expect to get at least a 3:1 capacity saving with an AFF, which has all the inline and automatic background post-process features enabled by default, and at least 2:1 with a FAS.
